
I am currently a PhD student at the University of Melbourne in Australia. My research journey is fully supported by the Melbourne Research Scholarship, and I’m incredibly fortunate to be supervised by Dr. Ting Dang and Prof. Eun-Jung Holden. Before joining Unimelb, I was an AI engineer at Fortemedia working with Dr. Rohan Kumar Das. I graduated as a CS Master student at NTU advised by Prof. Chng Eng Siong. I obtained my B.Eng degree from Jilin University.
I am contributing to building “adaptive”, “efficient”, and “robust” next-generation speech AI systems. At this moment, I mainly work in the post training paradigms for speech learning systems. Specifically, by merging continual learning, domain adaptation, knowledge editing, and reinforcement fine-tuning, we pave the way for speech models that continuously adapt, specialize efficiently, and self-correct in real-world environments. I have published more than 20 papers at the top international AI conferences and journals such as ACL, SPL, ICME, ICASSP, and INTERSPEECH.

🔥 News
- 2026.04: 🎉🎉 One paper has been accepted to ACL 2026!
- 2026.01: 🎉🎉 Four papers have been accepted to IEEE ICASSP 2026!
- 2025.12: 🎉🎉 Our ICME grand challenge ESDD 2 has been launched.
- 2025.11: 🎉🎉 Call for Papers: We will launch “Post-Training of Speech Foundation Models” at INTERSPEECH 2026 Special Sessions.
- 2025.10: 🎉🎉 I am honored to serve as a session chair in the APSIPA ASC 2025!
- 2025.09: 🎉🎉 One paper has been accepted to IEEE Signal Processing Letters 2025!
- 2025.09: 🎉🎉 Our ICASSP grand challenge ESDD 2026 has been launched.
- 2025.05: 🎉🎉 Four papers have been accepted to Interspeech 2025!
🔍 Research Area
Speech and Audio Processing: Sound Event Detection, Spoken Keyword Spotting, Speech Foundation Model, DeepFake Detection
Algorithm: Continual learning, Test time adaptation, Knowledge editing
🎓 Educations
- 08.2025 - Now, Doctor of Philosophy - Engineering and IT, The University of Melbourne, Australia
- 08.2021 - 01.2023, Master of Science (Artificial Intelligence), Nanyang Technological University, Singapore
- 08.2016 - 07.2020, B.E. in Internet of Things Engineering, Jilin University, Changchun, China
💼 Work Experience
- 01.2023 - 08.2025, AI Engineer, Fortemedia Singapore
- 07.2020 - 05.2021, Software Engineer, China Mobile (Chengdu) Industrial Research Institute
📝 Publications
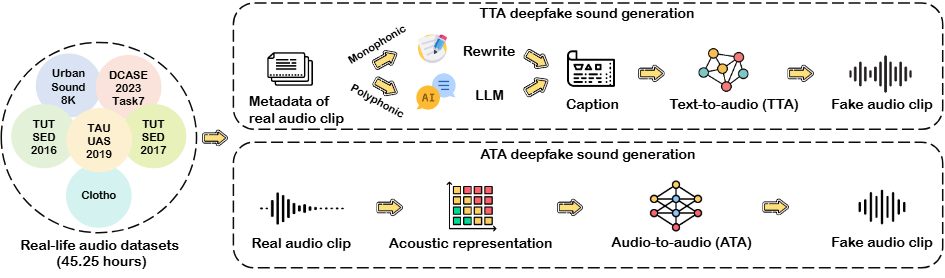
EnvSDD: Benchmarking Environmental Sound Deepfake Detection
Han Yin, Yang Xiao, Rohan Kumar Das, Jisheng Bai, Haohe Liu, Wenwu Wang, Mark D Plumbley.
- The first large-scale curated dataset designed for Environmental Sound Deepfake Detection.

XLSR-Mamba: A Dual-Column Bidirectional State Space Model for Spoofing Attack Detection
Yang Xiao, Rohan Kumar Das.
Continual Learning for Speech / Audio
ACL 2026Adapting Where It Matters: Depth-Aware Adaptation for Efficient Multilingual Speech Recognition in Low-Resource Languages, Yang Xiao, Eun-Jung Holden, Ting Dang.ICASSP 2026AFT: An Exemplar-Free Class Incremental Learning Method for Environmental Sound Classification, Xinyi Chen, Xi Chen, Zhenyu Weng, Yang Xiao.INTERSPEECH 2025Listen, Analyze, and Adapt to Learn New Attacks: An Exemplar-Free Class Incremental Learning Method for Audio Deepfake Source Tracing, Yang Xiao, Rohan Kumar Das.ACL 2025AnalyticKWS: Towards Exemplar-Free Analytic Class Incremental Learning for Small-footprint Keyword Spotting, Yang Xiao, Peng Tianyi, Rohan Kumar Das, Yuchen Hu, Huiping ZhuangICME 2025Where’s That Voice Coming? Continual Learning for Sound Source Localization, Yang Xiao, Rohan Kumar Das.ICASSP 2025UCIL: An Unsupervised Class Incremental Learning Approach for Sound Event Detection, Yang Xiao, Rohan Kumar Das.ICASSP 2025Dark Experience for Incremental Keyword Spotting, Tianyi Peng, Yang Xiao.DCASE 2022Continual Learning For On-Device Environmental Sound Classification, Yang Xiao*, Xubo Liu*, James King, Arshdeep Singh, Eng Siong Chng, Mark D. Plumbley, Wenwu Wang.INTERSPEECH 2022Rainbow Keywords: Efficient Incremental Learning for Online Spoken Keyword Spotting, Yang Xiao, Nana Hou, Eng Siong Chng.
Domain adaptation for Speech / Audio
INTERSPEECH 2025AdaKWS: Towards Robust Keyword Spotting with Test-Time Adaptation, Yang Xiao, Tianyi Peng, Yanghao Zhou, Rohan Kumar Das.APSIPA ASC 2025DG-SED: Domain Generalization for Sound Event Detection with Heterogeneous Training Data, Yang Xiao, Han Yin, Jisheng Bai, Rohan Kumar Das.DCASE 2024WildDESED: An LLM-Powered Dataset for Wild Domestic Environment Sound Event Detection System, Yang Xiao, Rohan Kumar Das.
Others
2026
ICASSP 2026Temporally Heterogeneous Graph Contrastive Learning for Multimodal Acoustic event Classification, Yuanjian Chen, Yang Xiao, Jinjie HuangICASSP 2026Environmental Sound Deepfake Detection Challenge: An Overview, Han Yin, Yang Xiao, Rohan Kumar Das, Jisheng Bai, Ting Dang2025
SPL 2025Noise-Robust Sound Event Detection and Counting via Language-Queried Sound Separation, Yuanjian Chen, Yang Xiao, Han Yin, Yadong Guan, Xubo Liu.INTERSPEECH 2025TF-Mamba: A Time-Frequency Network for Sound Source Localization, Yang Xiao, Rohan Kumar Das.SPSC 2025Multilingual Source Tracing of Speech Deepfakes: A First Benchmark, Xi Xuan, Yang Xiao, Rohan Kumar Das, Tomi Kinnunen.APSIPA ASC 2025RawTFNet: A Lightweight CNN Architecture for Speech Anti-spoofing, Yang Xiao, Ting Dang, Rohan Kumar Das.ICASSP 2025Exploring Text-Queried Sound Event Detection with Audio Source Separation, Han Yin, Jisheng Bai, Yang Xiao, Hui Wang, Siqi Zheng, Yafeng Chen, Rohan Kumar Das, Chong Deng, Jianfeng Chen.Before 2024
INTERSPEECH 2023Small Footprint Multi-channel Network for Keyword Spotting with Centroid Based Awareness, Dianwen Ng, Yang Xiao, Jia Qi Yip, Zhao Yang, Biao Tian, Qiang Fu, Eng Siong Chng, Bin Ma.
😁 Academic Services
- Session Chair: APSIPA ASC, INTERSPEECH, ICASSP
- Organizer: APSIPA ASC Special Session (ESPRESSO 2025), ICASSP Grand Challenge (ESDD 2026)
- Conference Reviewer: INTERSPEECH, ICASSP, ICME, IJCNN, APSIPA ASC, DCASE
- Journal Reviewer: IEEE TASLP, IEEE SPL, Pattern Recognition, EURASIP
🎖 Honors and Awards
- 2025.07 ISCA (International Speech Communication Association) Grant, Interspeech, Rotterdam
- 2025.03 Melbourne Research Scholarship, University of Melbourne